
During the last few weeks, I have been hearing more and more about AI agents: agents powered by LLMs that are able to “interact” with an environment - trigger actions or generate an answer (in the case of a simple LLM). It’s shaping up to be the next big thing in the corporate AI buzz.
But let’s get real for a second. Just like every other tech fad, you need to take the grand promises of tech gurus with a hefty grain of salt. The field can be no different to past hypes, such as the blockchain frenzy of the late 2010s, where we witnessed an all-time high of funky IPOs and crypto and NFT-related scams becoming too commonplace.
This Agentic AI hype might be no different. An easy target for money-hungry entrepreneurs, overpromising the capabilities of their cute yet geeky-looking tiny handheld devices, hoping to get rich quickly from VC funding. The Rabbit M1 and Humane AI pin fiascos come to mind.
Let me tell you, as someone who works in the field, developing, fine-tuning, guardrailing and securing an LLM is not an easy task. Pointing a request to its correct action or response requires an incredible amount of example data, labeled by humans. Even in that scenario, we need to be extremely careful about letting a program trigger actions in other programs. In most scenarios, the outcome might be no bueno.
Anyway, let's get away from my doom rambling. I still think that Agentic AI is conceptually very cool and, if developed along with safer and more robust programming practices, quite promising even.
Last week, as I was researching some literature in reinforcement learning for an upcoming project, I came across a paper by Shinn et al., that demonstrate the ability of self-reflexion mechanisms to improve the response of an LLM, versus traditional numerical-only rewards.
Reflexion mechanisms in training Large Language Models (LLMs) via verbal reinforcement learning involve a system where the model can learn and adapt based on feedback provided in natural language. This process is designed to mimic how humans learn from conversations and interactions.
Unlike traditional reinforcement learning, which uses numerical rewards, VRL uses verbal feedback to guide the learning process. The feedback can be positive, negative, or corrective, and the model adapts its behaviour based on this input.
As opposed to our more-common basic LLM scenario, here are a few pieces tight together when we consider a self-reflexive agent, as we can see in the diagram below:
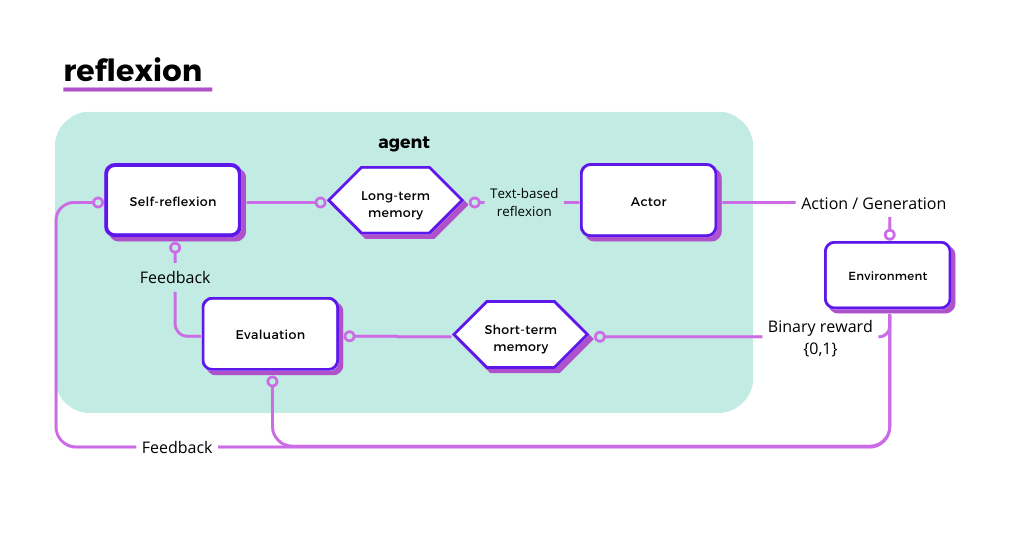
Components of the Reflexion Process
- Long-term memory: this component stores accumulated knowledge and experiences over extended periods. It includes both successful strategies and mistakes to ensure the agent can learn from the past.
- Actor: it is responsible for generating actions or responses based on the current state of knowledge (from both short-term and long-term memories) and the current context. These actions are then taken into the environment.
- The environment is where the agent operates and performs actions. It provides binary rewards (0 or 1) based on the success or failure of the actions taken by the agent. Keep in mind that usually the calculation of this reward is either automated or hard-coded, but rarely AI-generated.
- Short-term memory: This component retains recent experiences and feedback. Short-term memory is crucial for the agent to adapt quickly to new information and recent feedback before it is integrated into long-term memory.
- Evaluation: it involves assessing the outcomes of the actions taken by the actor. This can be done using feedback from the environment (binary rewards of 0 or 1) and verbal feedback. The evaluation process helps in determining the effectiveness of actions and strategies.
- Self-reflexion: the agent engages in self-reflexion, analysing its own actions and decisions based on the feedback received. This process likely involves introspective evaluation where the agent reviews what it has done, why it did it, and what could be improved.
Using self-reflexion is similar to closing the loop between the response generated by an LLM and our reply to the LLM, in a manner that the agent will give the prompt a couple of goes and iteratively evaluate its actions, till it arrives at a satisfactory result.
How does self-reflexion compare to Chain-of-Thought?
Alright, let’s break it down: chain-of-thought (CoT) versus self-reflexion. If you ask me, each has its own flair and finesse.
It could be easy to mistake CoT and self-reflexion. In a way, we are forcing the LLM to accomplish some sort of reasoning, right? Here is, however, the key difference:
- CoT doesn’t just spit out answers; it takes you on a journey through its reasoning process, step-by-step, so you can follow along. It’s the model equivalent of “showing your work” in math class, ensuring that every conclusion is backed by a clear line of thinking. It’s meticulous, it’s transparent, and it’s all about that logical flow.
- Self-reflexion, on the other hand, is all about looking inward, analysing past actions, and learning from its own experiences. Although constrained by token limits (and therefore, to look at 1-3 past experiences at a time), the actor in the loop takes past experiences in the long-term
So, while there’s a lot of hype around Agentic AI, we need to be cautious and focus on making it truly innovative and safe. The way I see it, the LLM field has not reached maturity yet, with yet many advanced prompting and optimisation techniques being researched. By leveraging self-reflexion and other advanced techniques, we can push AI beyond the hype and into something genuinely transformative.
What do you think about the potential of Agentic AI and self-reflexion? Are we on the brink of something revolutionary, or are we just riding the next hype wave? ✨ Share your thoughts! ✨