Hint: it’s neither the compute nor the size of the model
In the past couple of years, most of us have been witness to the boom of AI as a result of the discovery of Large Language Models (LLMs). LLMs have not been discovered overnight. In fact, they are a result of extensive research carried out in the field of Machine Learning, Natural Language Processing and applied mathematics, by academics and industry researchers alike.
Many attribute the surge of LLMs to the discovery of the transformer architecture. Introduced in the paper "Attention is All You Need" by Vaswani et al. in 2017, transformers have become the backbone of many state-of-the-art models. They build upon several techniques widely used in NLP research (the transformation of text into numerical representations or tokenisation, or sequential text analysis through Recurrent Neural Networks come to mind), but that might be a topic for discussion in a future article.
LLMs, as we know them today, are incredibly versatile: they can generate text, translate languages, and even write coherent essays, and even help you revive your sad-looking houseplants.
However, like all powerful tools, LLMs come with their own set of limitations.
Some of these limitations are quite obvious: the quality of the data used in training, the compute required to train an LLM, the cost of training and running an LLM - remember when Sam Altman asked UAE investors for 7 TRILLION dollars to produce GPU chips and train LLMs, anyone?
Some other bottlenecks in LLMs, on the other hand, are not that evident at first glance. One of them, the one I am going to ramble about here, is the (current) inability of LLMs to handle long in-context tasks.
What is in-context learning?
In-context learning is the capability to learn and adapt to specific tasks or instructions based on the context provided within the input text, without requiring additional training or fine-tuning. In other words, it is the ability to learn new things really quickly by itself, just by understanding what you show it right there and then.
Achieving such thing is a big deal, and one could argue such a system could qualify as AGI. The problem? We are quite far from that. Yet.
To give you an overview of how in-context learning works, we first need to think of how we are going to feed the “examples” to the model. We can do this using few-shot learning (showing the model some question-and-answer sets) or plain instructions (feed it clear task descriptions and instructions). This way, ideally, the model should be able to recognize patterns in the context and understand what to do next.
This sort of learning ability, if you ask me, sounds quite human-like.
Imagine you want to create a cooking assistant LLM. You “teach” it how to use a pan and an oven, how they work and a few recipes here and there. You decide to bring a new cooking tool into your kitchen, a steamer. This time, however, you decide to just tell your cooking buddy what the steamer looks like and what steaming does to food. You hope your model will figure out how to use the steamer and give you proper instructions for preparing your first steamed dumplings. The result? Most likely, your model will hallucinate and give you a set of instructions that will make you waste not only your time, but also your ingredients and money.
It is crucial to understand that in-context learning is not true learning in the traditional sense. Rather than updating its underlying parameters or knowledge base, the model is engaging in a form of dynamic task adaptation. This distinction means that LLMs are limited in their ability to truly expand their knowledge or capabilities through in-context learning.
What truely limits the ability of LLMs to learn through context comes back to the data. Imagine we could somehow lay out all ground truths to ever be known in a two-dimensional surface. A sizeable part of it could be considered what humankind has discovered and knows to this day (the purple area in the diagram below). A typical LLM is trained in a very small fraction of our knowledge - even smaller than the one represented by the blue area below - and this is because quality data is scarce, but also because training LLMs is still very costly.
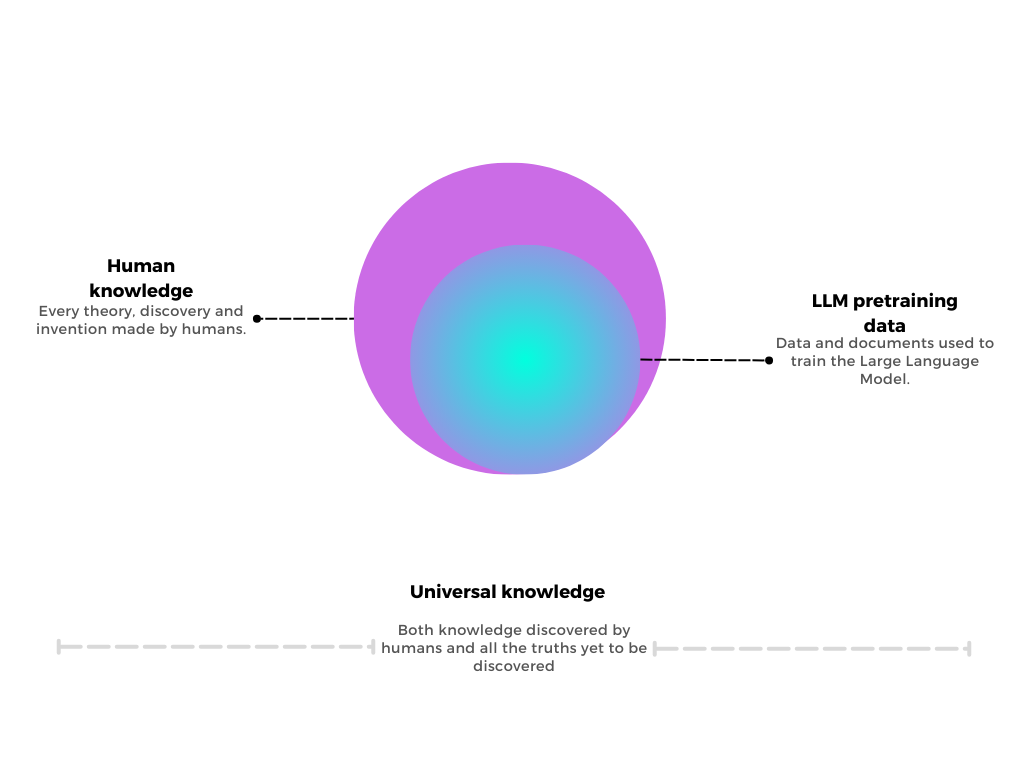
Following the diagram, in-context learning is limited to the area covered by training data, in blue. As we go further outside and reach the edges, LLMs behaviour is quite unpredictable and a good deal of hallucinations are bound to happen.
Moreover, in-context learning lacks true long-term memory. While LLMs can adapt to new information within a conversation, they cannot retain this knowledge beyond the current interaction. This means that any "learning" that occurs is transient and must be reintroduced in subsequent conversations, limiting the model's ability to accumulate knowledge over time.
There are a few ways we can improve this type of learning:
- The first and most straightforward way, which is by continuous training. If the model is frequently being trained "on the fly" as new and unseen data comes through, we could argue that the scope of LLM would widen and the model would, with time, be able to have increased inferring capabilities.
- By using sparse attention mechanisms: one of the most significant limitations is the finite context window of LLMs. These models can only process a limited amount of information at a time, typically ranging from a few thousand to tens of thousands of tokens. This constraint directly impacts the scope and depth of in-context learning, as it restricts the volume of information that can be provided for the model to work with. Sparsity allows models to process longer sequences of text by reducing the computational and memory requirements. This directly addresses one of the primary limitations of in-context learning - the finite context window. With sparse attention mechanisms, models could potentially handle much larger contexts, allowing for more comprehensive in-context learning scenarios. Additionally, sparsity can act as a form of regularization, potentially improving a model's ability to generalize from in-context examples to new, slightly different scenarios. This could help address the current limitation of poor generalization in in-context learning.
The rise of transformers is really a perfect storm of breakthroughs in how we build neural networks, figure out what's important in data, and work with sequences of information. It's pretty amazing how quickly these ideas have gone from research labs to powering the tech we use every day.
Think about it - whether you're Googling something, chatting with Siri, or getting Netflix recommendations, there's a good chance transformers are working behind the scenes. They've basically become the secret sauce in a lot of the AI we interact with without even realizing it. It's kind of wild how these complex math ideas have turned into tools that are shaping our digital lives in so many ways.
The future of AI is bright, and in-context learning is a shining example of how far we've come—and how much potential there is still to unlock. Let's engage with these AI systems, experiment with prompt engineering, and share our insights and experiences.
Together, we can turn the promise of AI into reality.